In this article, I will try to analyze the properties using 3 machine learning algorithms. This article will discuss the relationship between the facilities of a property that you want to offer to customers and discuss a system that will offer the most profitable property types using machine learning.
First of all, we need to import the library and the dataset that will be used in this project.
Import the library and dataset
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt
data = pd.read_csv("Property_Sales_Canberra_2006-2019.csv")
data
Here is the dataset :
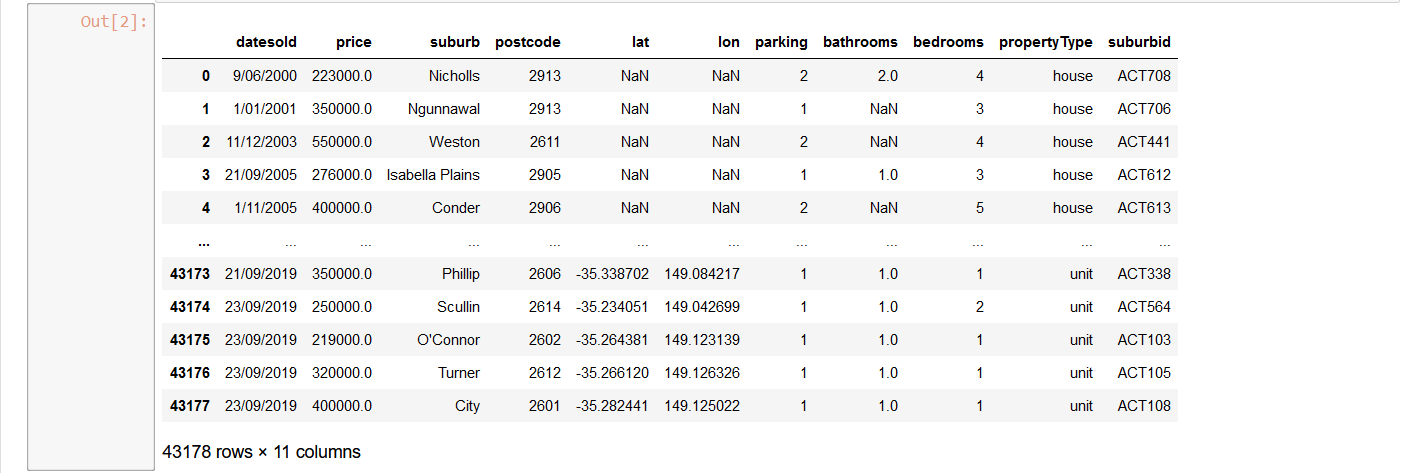
After we import the dataset, we need to clean the data. Hera are a few codes to clean the data.
Clean the data
clean_data = data.dropna(axis='rows')
clean_data
Then, we analyze the data using descriptive statistics. There are two types of descriptive statistics, univariate, and multivariate. Here are the univariate statistics.
Univariate
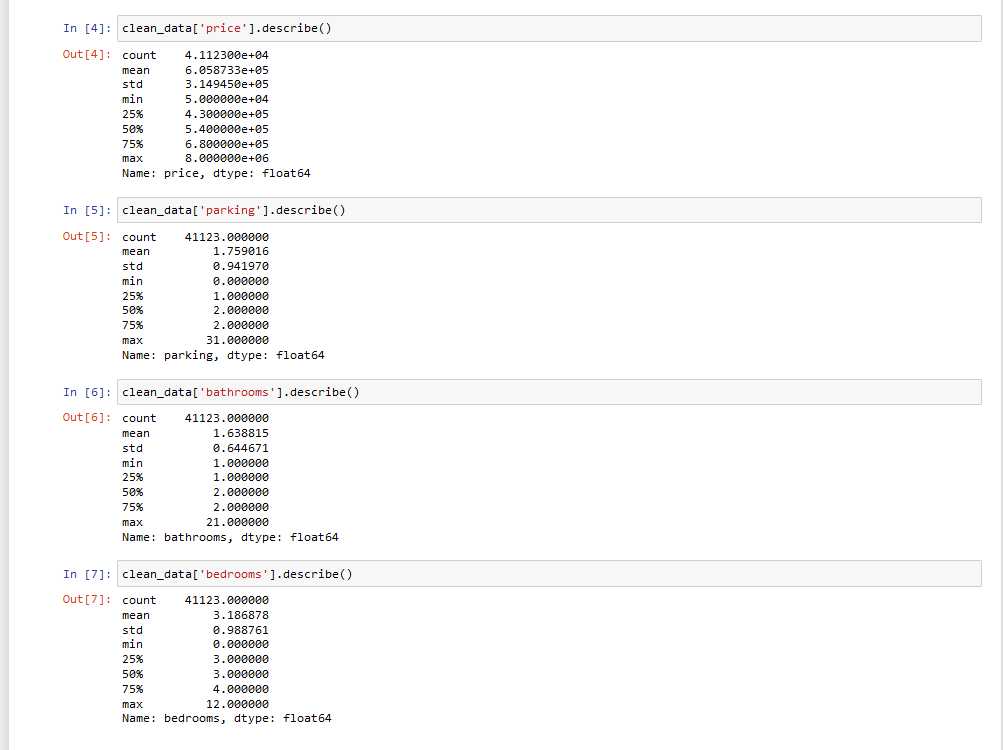
Here is the multivariate statistics.
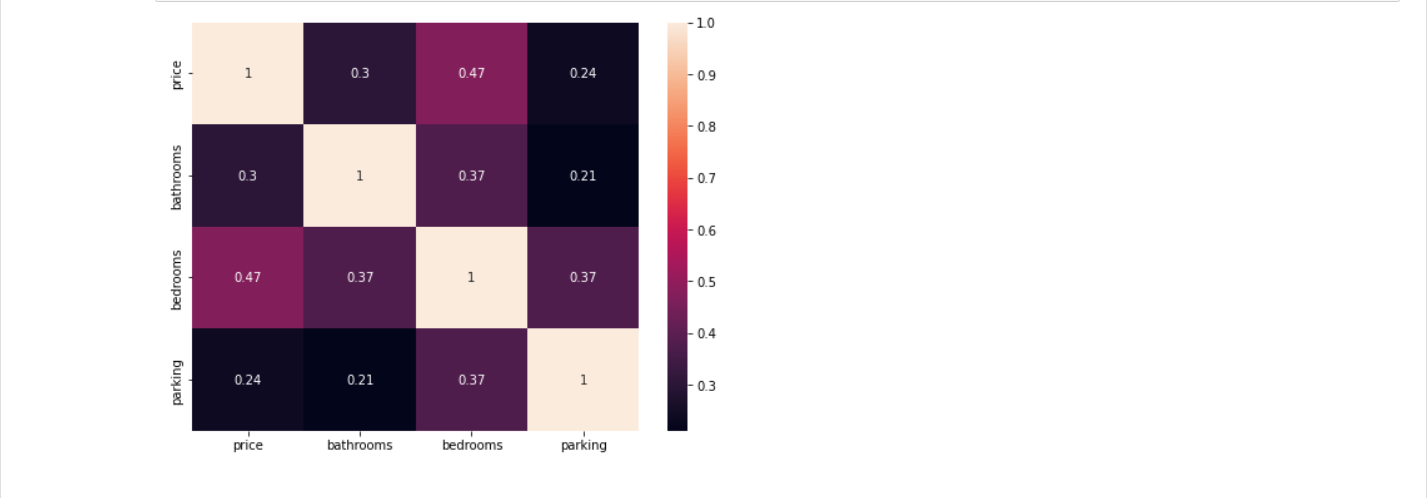
As you can see from the multivariate, there is no strong correlation between the number of amenities such as bathrooms, bedrooms, parking spaces, and the price of a property. Therefore it can be concluded from the data collected that the facilities do not affect the selling price of the property
After that conclusion, we proceed to build the model. There is a model that we will create using 3 algorithms, namely Decision Tree, Naïve Bayes, and Artificial Neural Network (ANN). First of all, we need to split the data into training and testing models.
Split the data
#Split the data into 70% data training and 30% data test
data_modeling = clean_data[['bathrooms', 'bedrooms', 'parking', 'price', 'propertyType']]
feature_cols = ['bathrooms', 'bedrooms', 'parking', 'price']
# Features
X = data_modeling [feature_cols]
# Target Variable
y = data_modeling.propertyType
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
Then, we use feature scaling for some of the algorithms that will be used for balancing the data.
Feature Scaling
# Feature Scaling untuk Naïve Bayes dan Artificial Neural Network
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
After all that process, finally we can create the model. Here are the models that we will create.
Decision Tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
#Create a Decision Tree Classifier
clf = DecisionTreeClassifier(max_depth=8)
#Train the model using the training sets
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Naïve Bayes
from sklearn.naive_bayes import GaussianNB
#Create a Gaussian Classifier
gnb = GaussianNB()
#Train the model using the training sets
gnb.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = gnb.predict(X_test)
Artificial Neural Network
import sklearn.neural_network
# Create a model
ann = sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', solver='adam',
alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5,
max_iter=1000, shuffle=True, random_state=42, tol=0.0001, verbose=False, warm_start=False, momentum=0.9,
nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08,
n_iter_no_change=10)
# Train the model on the whole data set
ann.fit(X_train, y_train)
#Predict the response for test dataset
y_pred = ann.predict(X_test)
After we created the model, we need to know whether the models are good or not. Therefore we created Confusion Matrix and Classification Report. Here are some of them :
Decision Tree

Naïve Bayes
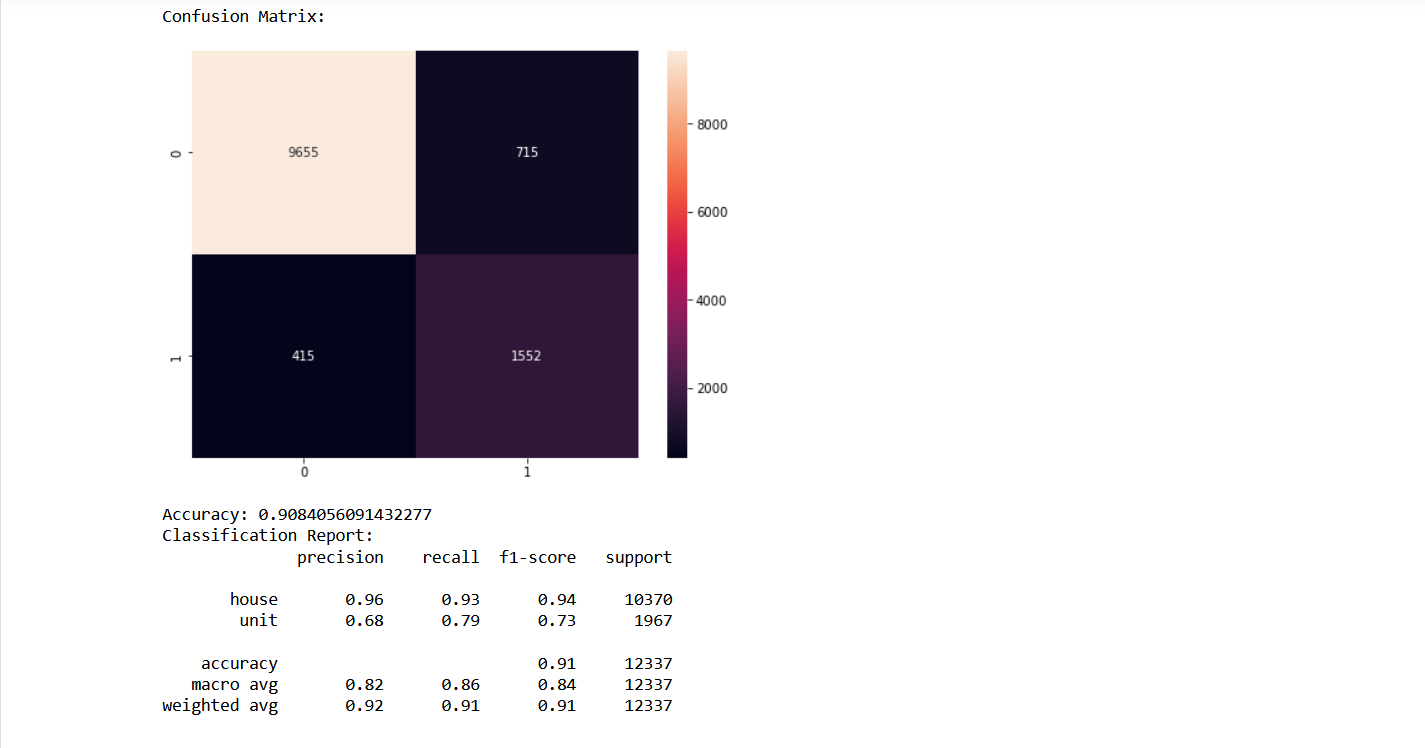
Artificial Neural Network
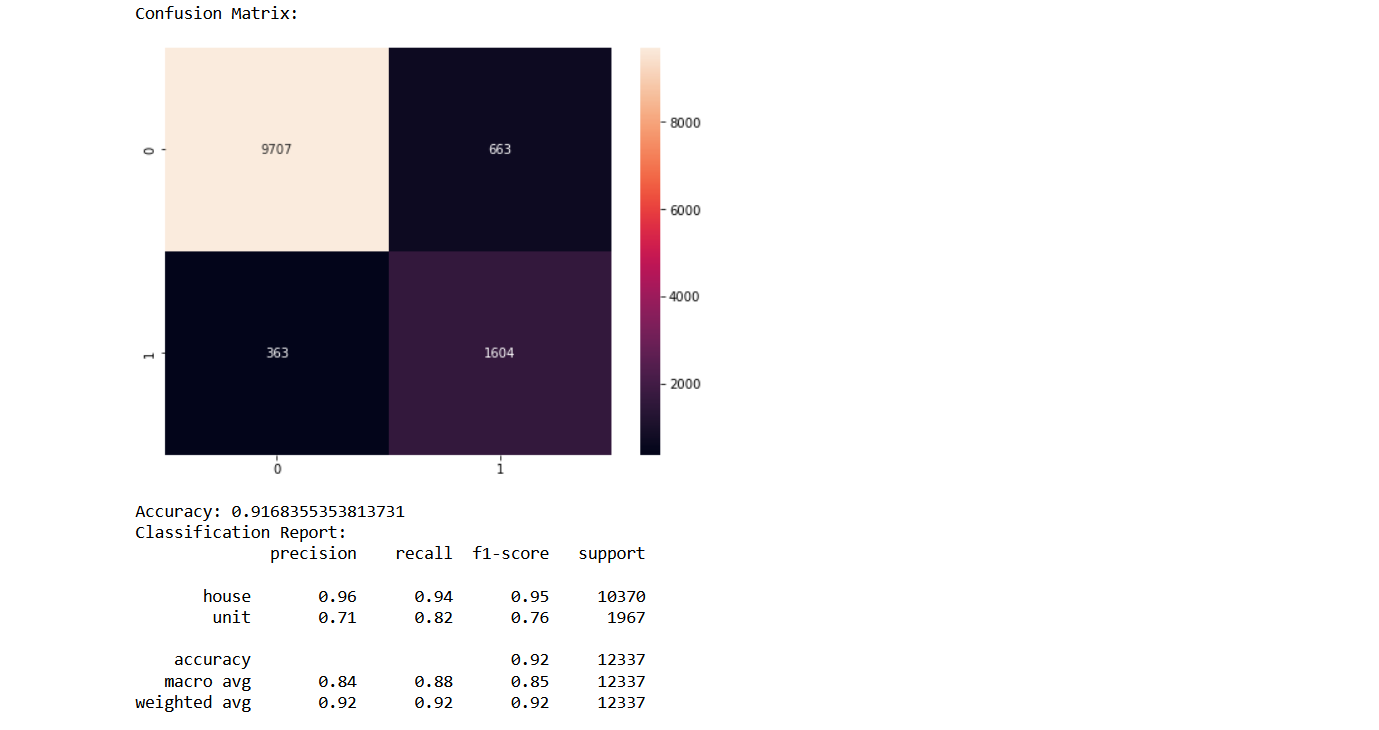
As we can see from the model, we can conclude that the best model that will be used for system that will offer the most profitable property types is Artificial Neural Network.That model produces 92% accuracy value, 82% recall value, 71% precision value and 76% f1-score value, which are better than the others.